Heap Data Structure — 1
Heap is an efficient data structure that can be implemented using an array, yes you heard that right. Heap can be visualized as a binary tree that is represented by an array. If you are not familiar with Binary Tree please explore that topic before dive into this article. Here is an example binary tree, not heap yet!. As you can see each node be can represent an element in an array.

If you carefully analyze the distribution of children's among parents, the index of left children is always smaller by 1, and index are increasing from left to right as depicted below.

This distributions gives a great advantage to represent a binary tree in an array. In order to implement binary tree we need to know how to figure out who is the parent, who is the right, and left child. Since we are using an array to implement this data structure, we need to know the appropriate index that is represents the child, and parent. Lets say we trying to find the left and right children for A[0] or root.
To find right child we use the following formula :

To find left child we can use the following formula :

So the two formulas can be used to find the right and left children for A[0]. So how do we find the parent of a child? Here is the formula :

The reason why number 1 is being added to the index and subtracted at the end is to ease the computation. Since arrays starts from index 0, its make difficult to find child and parent for example if we trying to find the left child of A[0], if we do not add 1 it will yield following result :
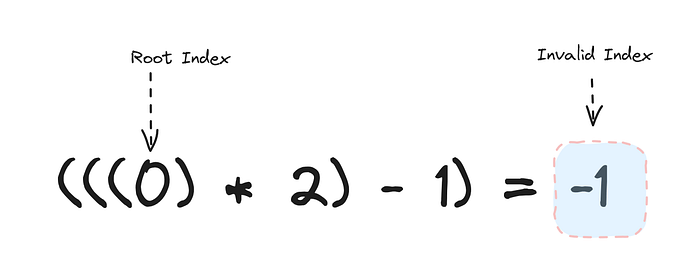
To avoid such a miscalculation, and adding 1 to the index is needed. The reason why we multiply by 2 is to find the children is because of the following structure if you notice that the child’s index is always 2 times bigger than its parent (Assume that we added 1 to each index). If we want to find the parent of a particular node since we know the child’s index is always 2 times bigger than the parent, we just have to divide the index of it (adding 1 prior to division).

Here are the helper methods that can be used to find children, and parent in a heap:
https://gist.github.com/yousuf1997/c6fcd9b8a6ccd3ed09a80bd56bcf7b78
So far we have talked about how to find child, parent, and heap representation using arrays. Let’s dive into core functionalities of heap, how heap works under the hood whenever we insert, delete, and update. Prior to understanding the core mechanism of the heap, we have to define heap property of a heap. We can have min or max heap, the heap property of each follows :
For max heap — Each node below the parent is always smaller than the parent, which means the top node will always contain the max value compare to its sub tree. This property yields that the root of the tree is always has the maximum value.
For min heap — Each node below the parent is always bigger than the parent, which means the top node will always contain the min value compare to its sub tree. This property yields that the root of the tree is always has the minimum value.
How do we ensure this property is always achieved if some internal or too node is changed, and that violates the either max or min heap property. Here is where the two most important methods comes to picture: percolate and sift down.
Lets delve into the percolate method first, and refer the following max heap, which all nodes are satisfied the heap property, in which root contains the maximum value.

Lets say we change the 1 to 25,
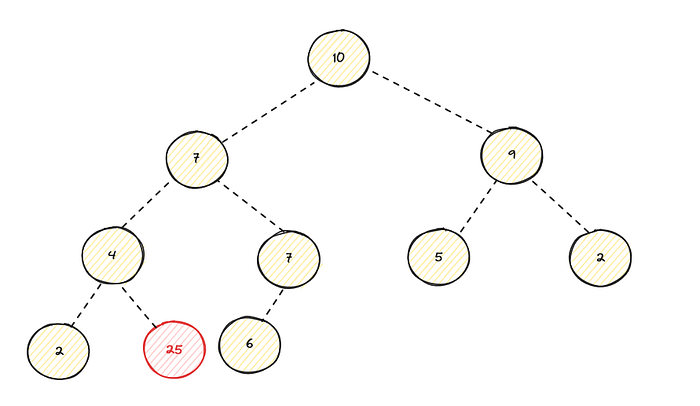
As you can see its violates the heap property, because its smaller than its parent which has value of 4 since this max heap. We have to percolate this value upward by swapping the parent with children (We already discussed how to find the parent in a heap, please refer above).
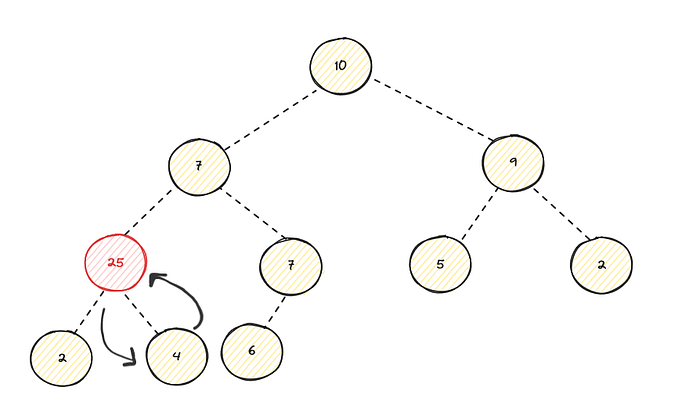
Ever after swapping, its still violates the max heap property since its new parent is also smaller than child, and so the operations continues :
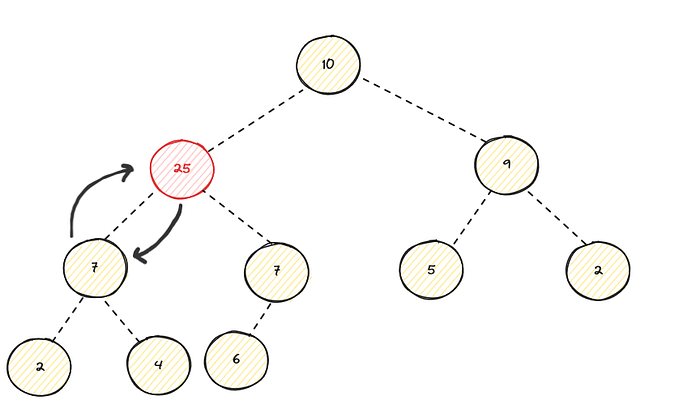
Still violates the heap property since its still bigger than its new parent, the percolate operation continues :
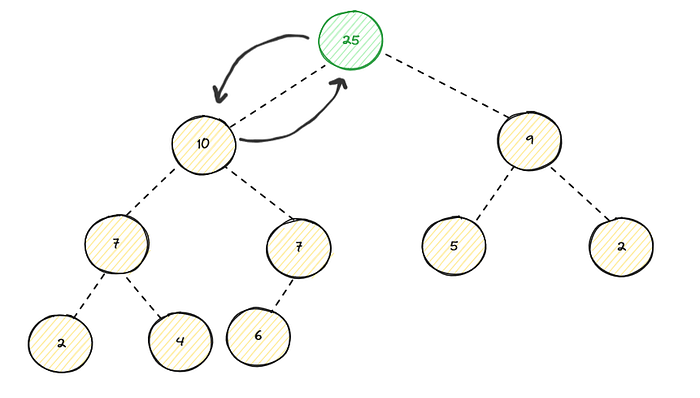
Now the heap property is restored since all parents are bigger than its children. In this case we have percolated up to the root, sometimes we stop at
the intermediate node, we just have to verify if the heap property is being met, then we stop. Here is the sample implementation of this method :
Now its time for sift down operation, as the name suggests we are trying to go downward this time. Lets refer the following max heap :
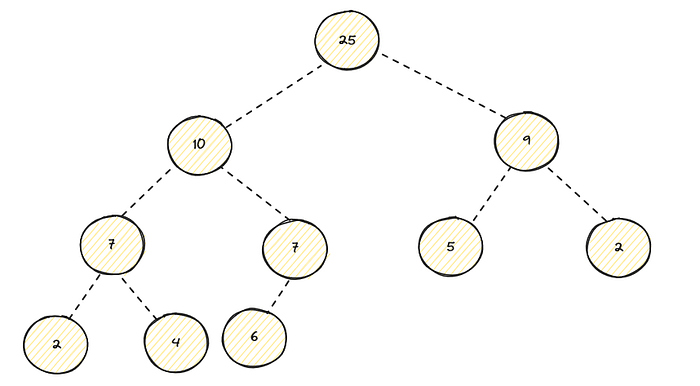
Lets change the root to -1 from 25 :
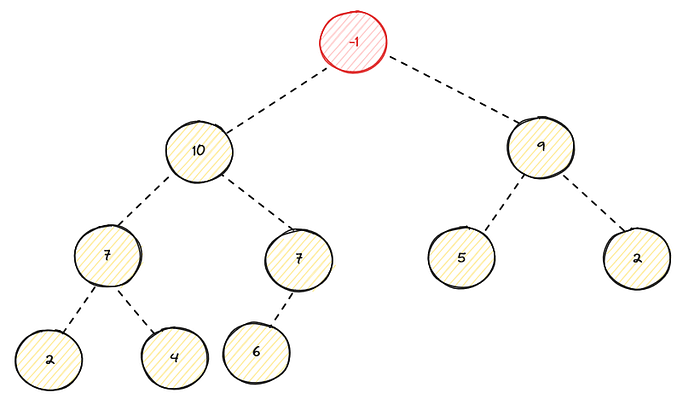
As you can see, it violates the heap property since the root is smaller than its children, since this max heap. So we have to bring this value to downward until it reaches the heap property. So we have to pick the largest children of the parent then we swap them, in this case 10 is bigger children :

As you can see its still violates the heap property , we continue the sift down operation, in this case both of its children have same value which is 7 we can pick either one, I will go with right child :
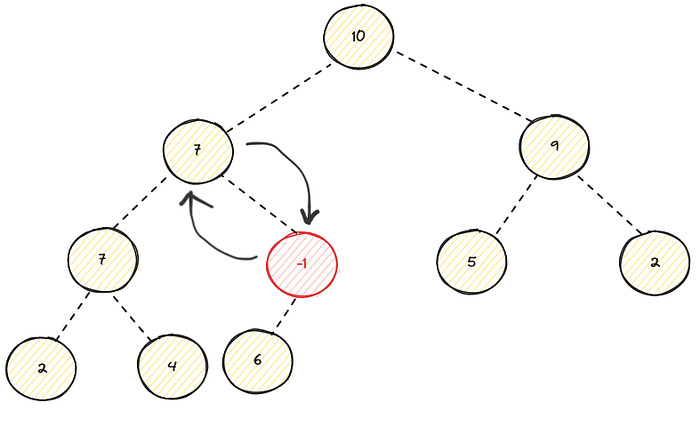
As you can see its still violates the heap property , we continue the sift down operation :
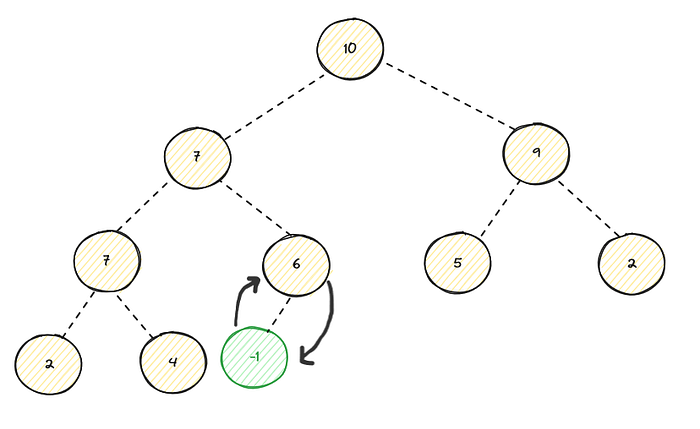
Now the the heap property is achieved, in this case we sift down to the leaves, but some times we might be stop at the intermediate node if its met the heap property. Here is the implementation of this method :
In this article we have discussed the core methods of the heap data structure, in next article we will delve into the other important methods and heap sort.
Reference :
Fundamentals of Algorithmics 1st Edition by Gilles Brassard (Author), Paul Bratley (Author)